
SMITH означает Siamese Multi-depth Transformer-based Hierarchical Encoder. Это новый алгоритм Google для обработки длинных текстов по длинным запросам. По качеству ответа SMITH превосходит BERT. Основное преимущество нового алгоритма в том, что он способен определять смысл фрагментов текста. BERT же определяет смысл отдельных лексем в контексте предложений.
В научной статье Google указывает, что:
The experimental results on several benchmark datasets show that our proposed SMITH model outperforms previous state-of-the-art Siamese matching models including HAN, SMASH and BERT for long-form document matching. Moreover, our proposed model increases the maximum input text length from 512 to 2048 when compared with BERT-based baseline methods.
Результаты тестов на выборках показывают, что предложенный нами SMITH превосходит предыдущие модели обработки длинного текста, включая HAN, SMASH и BERT. Более того, новая модель позволяет увеличить длину вводного текста с 512 до 2048 в сравнении с BERT.
Пока нет официальных подтверждений Google о том, что новый алгоритм применяется для обработки поисковых запросов.
Основное отличие SMITH от BERT
Разница в объеме рабочей единицы, а также в моделях обучения алгоритмов. Для BERT модель обучения предполагала прогноз скрытых в предложении слов. SMITH обучался прогнозировать как скрытые слова в предложениях и смысловых блоках, так и следующий фрагмент текста.
Для обучения SMITH была создана выборка рекомендованных документов из Википедии и ACL Anthology Network.
Как работает SMITH
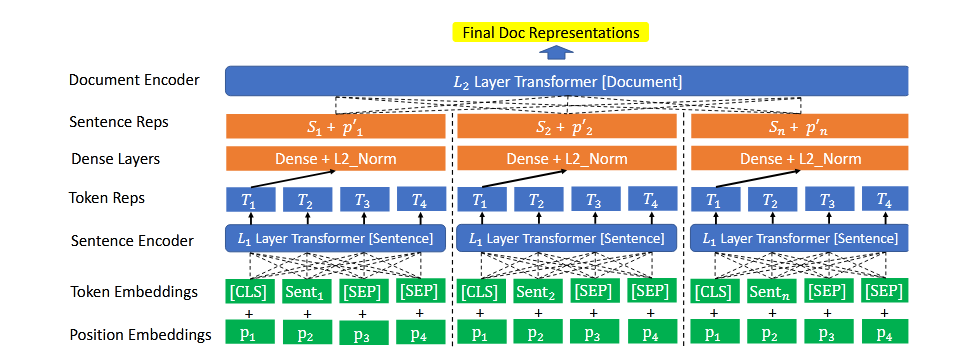
Алгоритм предполагает двухуровневую обработку текста. На первом уровне он разбивает текст на блоки, в которых могут быть от одного до нескольких предложений. Затем определяет соответствие поискового запроса в каждом из блоков.
На втором уровне обрабатывается последовательность блоков и наличие соответствий запросу во всем документе.
На уровне предложений алгоритм определяет взаимодействие “запрос — соответствие” в пределах блока. На втором уровне — взаимодействие “запрос — соответствие” в пределах текста для установления удаленных зависимостей.
Чтобы разбить текст на фрагменты, SMITH использует “greedy sentence filling” — метод, который в один блок помещает естественные предложения до точки. Алгоритм формирует блоки определенной длины. Предложения не разрываются между блоками. Если предложение не помещается в текущий блок, оно переносится в следующий.
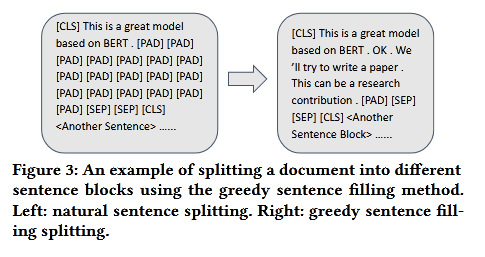
Если одно предложение превышает длину блока, алгоритм сокращает его так, чтобы оно поместилось в один блок.
Каждый документ D на входе трансформируется в последовательность блоков предложений {S1,S2,…,SLd}, а каждый блок S представлен последовательностью слов {Wi1,Wi2,…,WiLs}.
- Ld — длина документа по количеству блоков
- Ls — длина блока по количеству слов
Далее производится определение соответствий запросу на уровне предложений, блоков и всего текста. Учитывается количество вхождений и позиция вхождения в каждом анализируемом фрагменте (предложение, блок, текст). На уровне обработки блока учитывается позиция вхождения в предложении и позиция предложения в блоке.
Заключение
SMITH обучается анализировать текст на уровнях предложений, блоков (фрагментов) и целого текста.
Пока нет никаких заявлений Google о применении данного алгоритма в обработке поисковых запросов и формировании выдачи.
Учитывая суть алгоритма (сопоставление длинных запросов в длинных текстах) такой алгоритм вероятнее всего затронет небольшую часть поисковых запросов пользователей.
Также есть вероятность того, что Google таким образом готовится к будущей трансформации поисковых запросов. Уже сейчас запросы пользователей становятся более естественными, разговорными и развернутыми.
Одно из возможных применений алгоритма — повышение качества рекомендованного тематического контента, основываясь на том, что уже просматривал пользователь.
Эта публикация также доступна в Дзен-канале Миралинкс!
«Этот алгоритм большое подходит для повышения вовлеченности и создание подборок рекомендаций тематического контента, а не ранжирования документов.» — это что-то типа карусели в сниппетах выдачи гугла, только вместо картинок будет текстовая подборка ? Или как должна выглядеть вовлеченность ? По моему гугл и так дает открытый ответ выдирая из текста абзацы — например прогноз погоды или рецепт…
Вот такой момент, а если ответ на запрос пользователя в контенте «широкий» и мы не видим точные/неточные вхождения запроса по документу, что значительно уменьшает релевантность контента для любого типа запросов или групп необходимых запросов. И это при условии, что Гугл все еще не умеет «понимать» о чем этот «широкий» ответ = контент будет не релевантен и ВСЕ!
Как бы представители Гугла не «работали» над «улучшениями» (декабрское обновление показало откуда у них руки), у них до сих пор нет инструментов отличить оригинал от копипаста (в первоисточнике), а тут всякое машинное обучение и искусственный интеллект — на сегодня это = ФАНТАСТИКА И БОЛТОВНЯ. Категорически не верю!
Ах ну да, «Смит» еще тестируют и он сырой! Пока успешные кейсы только в головах разработчиков!
Ну да 🙂 звучит всегда здорово и замечательно, а вот когда доходит до дела… и так который год.
Но и не поделиться заявлением мы тоже не могли)
Идея впихивать ключевик в каждый абзац возвращается в новом цвете
Чуть чуть поправим Ваш вывод:
1. SMITH может не стать частью основного алгоритма ранжирования.
2. Этот алгоритм работаем с парой «длинный ключ — длинный документ», а не со всеми документами.
3. Google не указывает, что наличие соответствий в каждом абзаце является фактором ранжирования или что хоть каким-то образом влияет на релевантность.
Этот алгоритм большое подходит для повышения вовлеченности и создание подборок рекомендаций тематического контента, а не ранжирования документов. Мы бы не рекомендовали менять тактику оптимизации текстов на данном этапе.
А сейчас как? или у вас ключи только во вхождении в первый абзац и в конце текста? Всегда хорошим тоном считалось равномерное распределение ключей по тексту. Но тут ведь о другом идёт речь. О том что текст должен включать и более длинные и отдалённые запросы по тематике чтобы считаться более релевантным запросу.