Яндекс представил новый поиск Y1, в основе которого — генеративная нейросеть YaLM, построенная на архитектуре трансформеров. Генеративная означает создающая. Это более мощная версия с увеличенным в 4 раза числом параметров.
Основная задача Яндекса сейчас — давать точный ответ в минимальные сроки. Вводя запрос, пользователь ищет ответ или решение, а не конкретную страницу или сайт. Сейчас новая нейросеть подготавливает ответы только для Поиска Алисы, но со временем ее планируют развернуть и на обычный поиск.
Сбор обучающей выборки
YaLM означает Yet Another Language Model. Задача моделирования — заставить модель продолжить текст на основе анализа предыдущего фрагмента. Модель сначала изучает, как устроен язык (его грамматические и лексические связи), затем факты об окружающем мире, чтобы генерируемый текст был логичным и корректным. Чтобы обучить этому любую модель, нужна масштабная выборка текстов. Весь интернет — это слишком шумная выборка, с большим количеством некачественных текстов и дублей.
Для обучения YaLM были собраны тексты из словарей и энциклопедий, книг и авторитетных новостных источников. А чтобы увеличить объем выборки, к получившимся текстам были добавлены форумные обсуждения и комментарии из социальных сетей. Последний компонент датасета — “сырые” тексты из интернета, чтобы в итоге размер обучающей выборки достиг нескольких терабайт данных.
Обучение YaLM
Чтобы ускорить процесс обучения, Яндекс распределил задачу на большое количество видеокарт с хорошей сетью. Для этого использовались карты типа NVIDIA Ampere.
Есть несколько методов обучения. Один из них Data parallelism.
Каждая карта обучает модель на своем кластере данных. Другим же картам передает лишь градиент — результат, чтобы каждая другая карта получила обновленное с учетом новых данных состояние модели.
Но даже при обучении более упрощенной модели с 1 миллиардом параметров возможностей карт для обработки, хранения и передачи данных было недостаточно.
Чтобы оптимизировать процесс, применялся метод Pipeline parallelism. Его суть в том, что каждая из видеокарт применяет лишь некоторые слои модели, промежуточный срез передает следующей карточке, которая задействует полученные данные и следующие слои модели и т.д. Основной недостаток метода в том, что он вызывает простой мощностей оборудования.
Второй метод обучения Tensor parallelism — есть суть в том, что выделяются не поперечные слои модели, а продольные. Это позволяет избежать простоя мощностей, так как каждая карта выполняет свой кусок задачи. Основной недостаток — повышенное число коммуникаций и синхронизаций между видеокартами. Такой метод удобен лишь внутри хоста, когда обмен данными происходит по шине, а не по сети.
Третий метод — ZERO, его суть сводится к первому Data parallelism с тем отличием, что каждая видеокарта хранит лишь часть “знаний” о модели, а остаток запрашивает у других карт. Как только операция с ними состоялась, карта моментально забывает полученные данные. Карта применяет первый слой, запрашивает с соседней данные по второму слою, применяет их и моментально стирает из памяти. Недостаток — стабильность работы внутри хоста из-за высокой интенсивности обмена данными.
Чтобы обучить YaLM, Яндекс применил комбинацию безопасных методов, чтобы избежать потери точности данных.
Применение YaLM
Создание подзаголовков для объективных карточек ответов
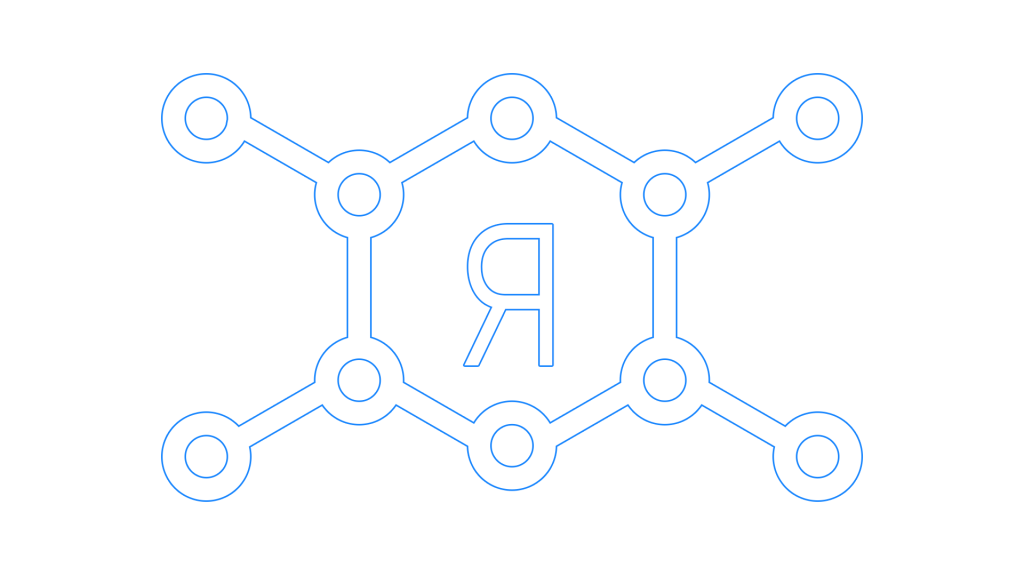
Яндекс создает сотни тысяч ответов, которые содержат описание объекта. Для этих карточек с ответами нужны заголовки, чтобы пользователь сразу мог понять, о чем пойдет речь, без изучения всего текста.
YaLM поддерживает обучение Few-shot learning — то есть возможность выполнять новые задачи без дополнительных тренировок. Модели достаточно “скормить” несколько примеров на естественном языке, чтобы она подхватила принцип и начала генерировать подобный текст, так как уже обладает достаточными знаниями об устройстве языка и окружающего мира. Такой микро-обучающий текст называется подводкой. Если она составлена удачно, то результат действий модели — правильный искомый ответ.
Основная проблема — создание той самой правильной подводки. Пока не существует набора критериев корректного текста для few-shot learning.
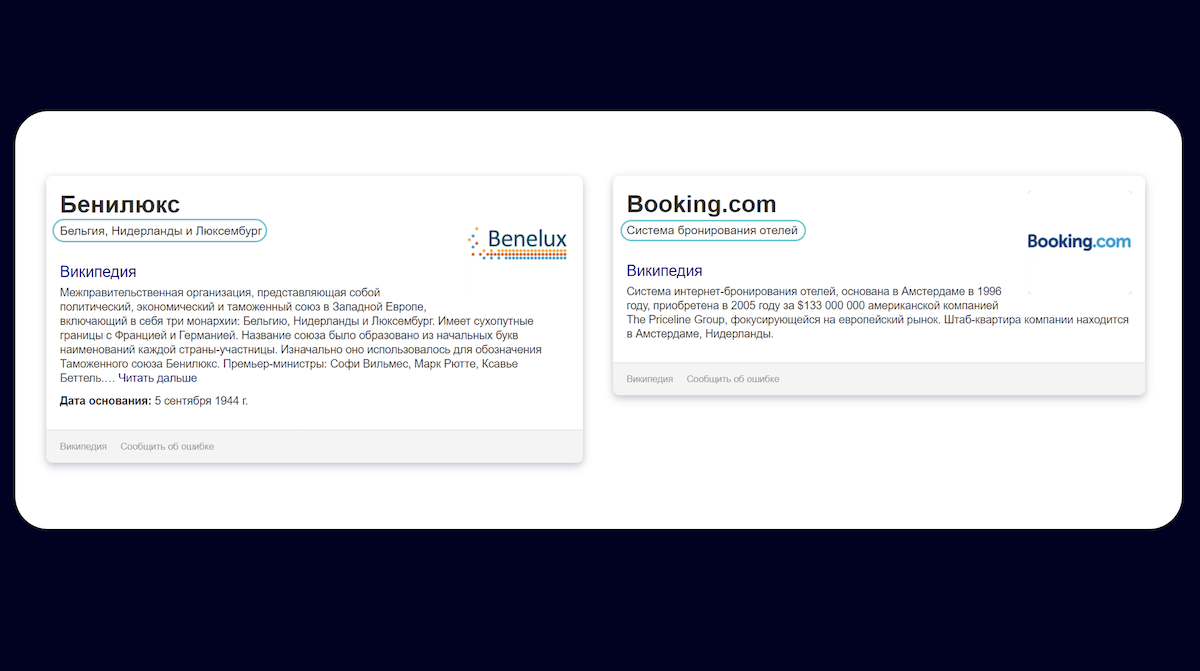
Ранжирование сниппетов
YaLM способна выполнять и задачи классификации по заданным признакам.
Ежемесячно Яндекс генерирует 130 миллионов быстрых ответов. Быстрый ответ — это достаточный фрагмент контента, чтобы ответить на запрос пользователя. Он показывается над результатами выдачи. Быстрые ответы создаются путем анализа подходящих фрагментов текста сайтов из топа выдачи, а затем алгоритм выбирает оптимальный.
Теперь для таких задач задействуются мощности YaLM.
Ответы для Алисы
YaLM генерирует реплики для Алисы, на входе модель получает контекст диалога. Задача — сформулировать следующую реплику. Обучение проводилось на ветках обсуждений из социальных сетей.
Дальнейшее применение YaLM
В планах Яндекса — развернуть модель на диалоги с Алисой и генерацию быстрых ответов в выдаче для экономии времени пользователей.
Этом материал также доступен на Дзен-канале Miralinks!
Точно так же, как и Гугл пытается доминировать — Яндекс в России дублирует политику. Просто инструменты выбираются другие и все… Каждый хочет урвать кусок пирога))) В Украине Яндекс вообще «скурили» поэтому потерялся огромный рынок, что остается? Воевать «на Родине»))))
Заметил, что Яндекс стал H1 в сниппете показывать вместо Title.
Яндекс замыкает весь интернет в себе. Интересно, будут ли суды как в Австралии за то, что они будут использовать чужие текста в Алисе? Весь интернет в яндексе. 🙂 За такие финты которые творит яндекс у себя, гугл уже закрылся бы давно (из-за судов).
А какой стране Яндекс все подмял? Китай 🙂 … По моему, как раз Гугл подминает, и все что остается Яндексу, хоть где-то преуспеть.. А на счет чужих текстов в соц.сетях, скорее всего Яндекс с соцсетью все согласовал. А сама соцсеть , маленькими буковками, предупредила пользователя.Так что все айс.