
Google представляет самое масштабное поисковое обновление за последние 5 лет. Теперь основной алгоритм дополнит технология Bidirectional Encoder Representations from Transformers, основанная на машинном обучении. Модель обучена по-другому обрабатывать поисковые запросы, чтобы лучше извлекать смысл и намерение и показывать релевантный ответ. Сегодня новая модель обрабатывает 10% англоязычных поисковых запросов.
Принципы работы BERT
Новая модель обучена обрабатывать слова в запросе в связке с другими словами из предложения. Модель учитывает контекст, в котором выступает слово, чтобы выбрать точное значение, подразумеваемое пользователем.
По прогнозам, BERT будет обрабатывать до 10% запросов, для которых у поискового алгоритма нет готового (проверенного) ответа. Модель обрабатывает сложные длинные запросы, сочетания с предлогами, которые могут сильно изменить смысл.
Основная цель внедрения новой модели — улучшенное понимание естественной речи человека.
Что нужно знать вебмастерам и оптимизаторам
BERT не вносит ничего принципиально нового в ранжирование.
Новая модель обработки данных применяется лишь для тех запросов, по которым у поисковой системы нет готовых ответов. Каждый день Google получает до 15% запросов, с которыми раньше не встречался либо смысл которых ему не понятен.
BERT работает не с контентом, а с поисковым запросом. Его задача — трансформировать запрос так, чтобы он стал понятен поисковой системе. Извлекая точные смыслы и сопоставляя их со смыслами документа, алгоритм сможет показывать более релевантные и полезные ответы пользователю.
BERT затронет только 10% поисковых запросов, как правило, это длинные низкочастотные запросы.
Нововведение не требует никаких изменений ни в существующем контенте на сайте, ни в подготовке нового контента. Просто стоит учесть, что поисковые алгоритмы (как Google, так и Яндекс) учатся лучше понимать естественную человеческую речь. Сегодня текстам уже не требуются точные частые вхождения ключей, чтобы показать поисковой системе релевантность страницы.
Аналоги BERTa
Аналогичные модели обработки запросов использует и Яндекс (Палех, Королев), что позволяет российскому поисковику строить более точную выдачу.
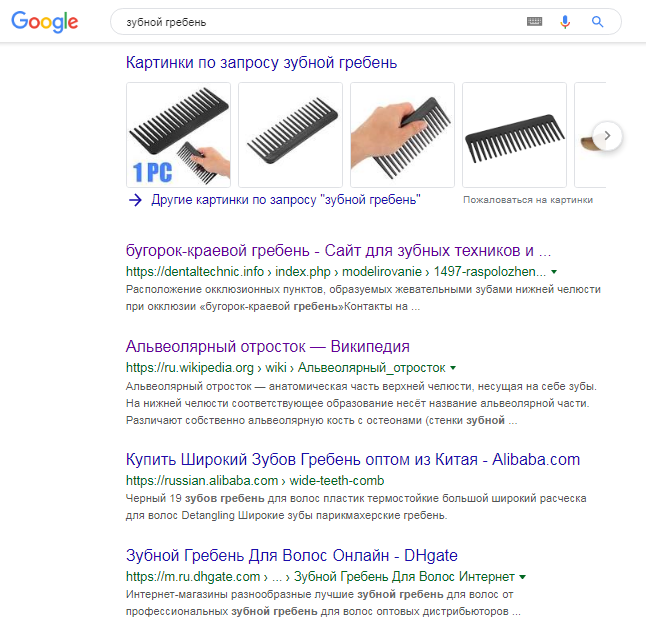
Посмотрим на реальных примерах. В стоматологии есть понятие зубного гребня. Спрашиваем у Google и Яндекса.
Google:
Продолжение той же выдачи:
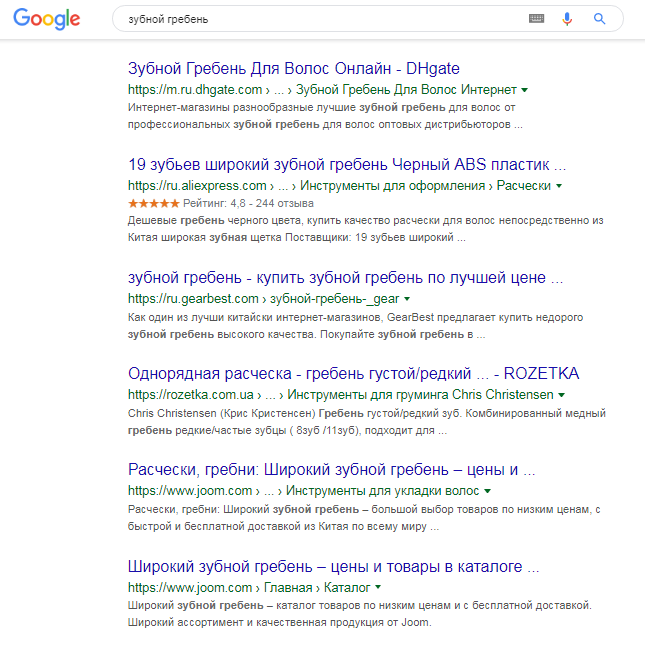
Только первые два результата имеют отношение к стоматологии, но не объясняют запрос. Являются нерелевантными. Google далее показывает сайты, на которых можно купить расчески. Видимо, основной алгоритм посчитал, что пользователь имеет в виду гребешок.
Яндекс:

Продолжение той же выдачи:
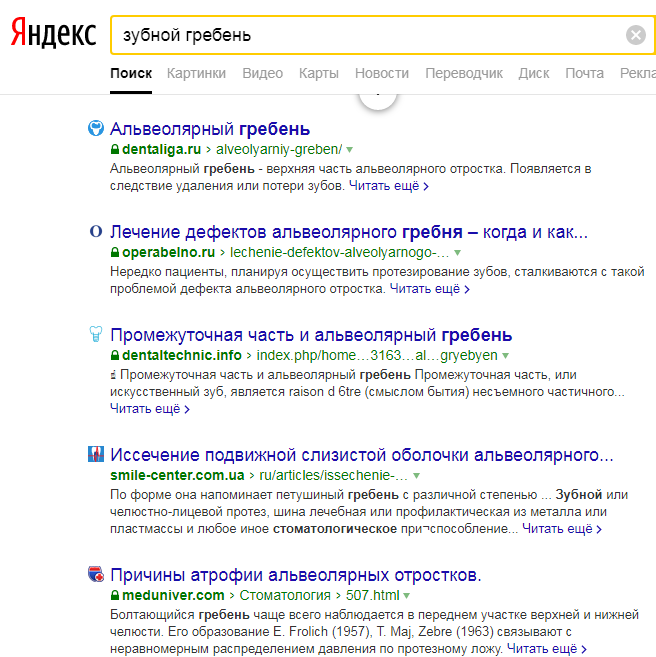
Яндекс показал результаты соответствующей тематики. Возможно, BERT приблизит Google к лучшему пониманию запросов.
Пример показывает, как неправильная интерпретация запроса поисковой системой дает сбой в выдаче. Пользователь не получает ответ, сайт не получает клиента.
Согласен, статья информативна. Как говориться, держим руку на пульсе.
Спасибо автору за статью, очень интересно по алгоритмам